
서울대 산업공학과, 미 프린스턴대 금융공학 박사, SSCI 학술지 ‘Quantitative Finance’편집장, 신한-카이스트 AI금융연구센터 센터장
어떤 배우의 황당한 사연을 유튜브에서 우연히 접하게 됐다. 코끼리가 돌아다녀 생긴 교통체증 때문에 촬영장에 늦게 도착했는데, 이유를 설명해도 PD가 믿어주기는커녕 욕을 해 아주 억울했다는 것이다. 어린이대공원에서 사육되던 코끼리 여섯 마리가 탈주한 사건으로 2005년 당시 9시 뉴스에도 나왔던 일이라고 한다. 서울 시내에 코끼리 난입이라니, 믿어주지 않았던 PD도, 황당했던 배우의 심정도 이해가 간다.
인공지능(AI) 기반 자율주행차가 이런 황당한 상황을 맞닥뜨렸을 때 어떤 반응을 할까. 코끼리가 서울 시내 도로를 뛰어다녔다는 소식은 이 사건 이후로 알려진 바 없다. 따라서 이런 특수한 상황, 즉 에지 케이스(edge case·극단적인 경우)를 자율주행차가 학습했을 것으로 생각하기 어렵다.
따라서 정답은 ‘아무도 모른다’이다. 인공지능, 특히 지도학습(supervised machine learning)은 통계적인 패턴 인식 방법론이다. 새로운 문제의 답을 과거에 학습한 데이터, 즉 답이 표시된 문제들을 기반으로 통계적으로 찾아내는 것이 인공지능의 원리다. 인공지능이 한 번도 보지 못한 완전히 새로운 문제에 어떤 답을 하게 될지 미리 알아내는 것은 본질적으로 매우 어렵다. 자율주행차가 코끼리를 보고 안전하게 멈추는 것도, 잽싸게 피해 가는 것도, 들이받는 것도 모두 가능한 일이다. 인공지능은 상식이 없다.
아주 유명한 사례가 하나 있다. 2018년, 구글 번역에 강아지를 뜻하는 ‘dog’를 19번 입력한 후 마오리족 언어에서 영어로 변환시키면 “종말의 시간이 3분 앞으로 다가왔다(Doomsday Clock is three minutes at twelve)”라거나 “예수의 재림이 머지않았다(We are increasingly approaching the end times and Jesus' return)” 등의 종교적인 텍스트가 출력됐다. 구글은 이상하다 못해 섬찟한 이 사례에 대해 논평하기를 거부했다.
외부의 해석은 크게 두 가지다. 첫 번째, 내부인이 학습 데이터에 장난을 쳤을 가능성이다. 하지만 구글 번역은 학습 데이터의 오염을 사전적으로 필터링하는 절차를 밟는다는 것을 고려하면 이는 설득력이 떨어진다.
두 번째 해석은 지도학습 알고리즘 특성에 기반한다. 구글 번역을 학습시키기 위해서는 한 언어로 쓰인 텍스트와 그에 상응하는 다른 언어의 번역된 텍스트가 많이 필요하다. 마오리족 언어는 영어와 1대1로 매칭되는 번역 텍스트가 많지 않았기에 학습에 ‘성경’을 활용했을 가능성이 있다. 19번 반복된 ‘dog’라는 텍스트는 구글 번역이 단 한 번도 보지 못했기에 실질적으로는 무작위적인 결괏값을 출력하게 됐고, 마침 학습에 사용된 ‘성경’의 한 구절이 튀어나왔다는 것이다. 필자는 이것이 정확한 설명이라고 생각한다.
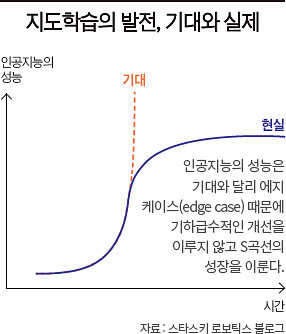
서울 시내에 나타난 코끼리에게 자율주행차가 어떻게 반응할지에 대한 사고실험, 그리고 의미 없는 입력값에 예수의 재림을 출력하는 구글 번역 사례가 시사하는 점은 인공지능이 제대로 작동하기 위해서는 좋은 학습 데이터, 특히 잘 발생하지 않는 ‘에지 케이스’ 학습이 필수적이라는 것이다. 여기서 인공지능의 성능 개선에 대한 중요한 딜레마가 발생한다. 에지 케이스는 잘 발생하지 않기 때문에 학습에 필요한 충분한 데이터를 얻는 것이 어렵다. 데이터 획득 이전에 코끼리가 서울 시내 도로에서 뛰어다닐 수 있다는 사실을 인지하는 것조차 어려운 일이다. 따라서 지도학습을 통한 인공지능의 성능 개선은 초반에는 매우 빨리 이뤄지지만, 어느 정도 수준에 오른 이후로는 정체되는 ‘S곡선’ 형태의 성장을 할 수밖에 없다.
2019년 세계 최초로 실제 고속도로에서 운행하는 무인트럭을 만들어 낸 미국의 스타트업 자율주행트럭 업체 스타스키 로보틱스가 유니콘(기업 가치 10억달러 이상의 비상장 기업)에 등극한 지 불과 1년 만인 2020년 3월에 폐업한 것도 바로 이 딜레마를 극복하지 못했기 때문이다. 창업주인 셀츠-악스마커는 폐업 이유를 “지도학습이 선전된 바를 달성하지 못했기 때문(supervised machine learning doesn’t live up to the hype)”이라고 단언했다. 그럭저럭 작동하는 인공지능은 빠르고 저렴하게 만들어낼 수 있었지만, 인간을 대체하는 수준까지 성능을 끌어올리려니 터무니없는 시간과 비용 증가가 발생했으며, 나아가 그것이 가능한 것인지조차 알 수 없다는 것이다.

‘로봇세로 기본소득 재원 마련’ 허울 좋은 포장
기술이 노동으로부터 인간을 해방할 수 있을까. 알파고가 새로운 세상을 여는 신호탄을 쐈던 4년 전보다는 기대 수준이 많이 낮아진 것만은 확실해 보인다. 아니, 불과 1년 전과 비교해봐도 인공지능이 금방 산업현장에서 인간을 대체할 것이라는 주장은 상당히 힘을 잃은 모양새다. 스타스키 로보틱스가 좋은 예다.
이는 현재 활발히 일어나는 기본소득 논의에 중요한 함의를 갖는다. 기본소득의 걸림돌은 결국 재원이다. 인공지능이 다른 기술의 산물들과 같이 생산의 보조수단에 머무르게 된다면 로봇세, 즉 인공지능의 잉여생산에 대한 과세를 통해 기본소득의 재원을 마련할 수 있다는 주장은 허상일 뿐이다. 물론 알파고급의 기술 혁신이 앞으로도 몇 번 더 일어나 우리가 노동으로부터 해방될 수도 있다. 하지만 이는 가정일 뿐이다. 이는 ‘7광구가 북해 유전만큼 대박이 날 수 있으니 우리 국민의 노후는 문제없다’는 주장이나 다름없다.
기본소득에 많은 사람이 관심을 두는 이유는 이것이 우리 사회의 가장 큰 병폐인 양극화에 대한 구조적 완화 장치가 될 수 있기 때문이다. 현재 일어나고 있는 기본소득에 대한 논의는 국가 공동체의 지속 가능성 확보 차원에서 아주 중요하다. 진지하고 또 치열하게 다뤄질 필요가 있다. 결국 핵심은 누가 돈을 내느냐다. 현시점에서 로봇세로 기본소득 재원을 마련하겠다는 주장은 생산수단에 대한 과세, 즉 법인세 인상의 허울 좋은 포장일 뿐이다. 사설 연구소나 시민단체는 충분히 할 수 있는 이야기지만 정치 지도자들은 그래서는 안 된다. 냉철한 현실 인식 없는 장밋빛 주장은 모처럼 형성된 기본소득 논의를 허사로 만들 뿐이다.
인공지능과 로봇이 인간을 노동으로부터 해방해줄 유토피아 같은 미래가 열리기를 바라지 않는 사람이 어디 있으랴. 필자도 기본소득을 지지하는 입장이다. 또 공학자로서 인공지능의 발전에 큰 기대와 희망을 걸고 있다. 하지만 현재의 인공지능은 인과관계를 이해하지 못한다. 인간의 학습이 인과관계의 유추를 통한 지식의 일반화를 의미하는 것과 대비되는 지점이다. 게다가 인공지능의 내부 구조는 본질적으로 블랙박스다. 인공지능은 상식이 없다. 기본소득에 대한 논의는 4차 산업혁명이라는 거대 담론에서 출발한 만큼, 이러한 기술의 가능성과 한계에 대한 명확한 이해를 바탕에 두고 진행해야만 한다.