회사에 출근하기 위해 아침 8시에 집을 나서는 A씨. 집 앞에 있는 지하철역으로 들어가 지하철을 타고 회사로 향한다. 지하철로 이동하는 도중 A씨는 페이스북에 접속해 친구들의 근황을 확인하고 마음에 드는 글에는 ‘좋아요’(Like)를 누르거나 댓글을 단다. 지하철을 타고 30분쯤 지나 사무실이 있는 광화문역에 도착했다. 체크카드 계좌에 돈이 떨어진 것을 확인한 A씨는 역 앞에 있는 은행에 들어가 돈을 입금한다. 퇴근 후 친구들과 만나 저녁 식사를 하고 2차로 맥주 몇 잔을 걸친 A씨는 밥값과 술값의 n분의 1 비용을 친구에게 모바일 뱅킹으로 계좌 이체한다. 버스정류장에서 버스를 기다리던 A씨는 술이 들어가서인지 갑자기 외로워졌고, 그는 버스정류장에서 버스를 기다리며 전 여자친구에게 전화를 건다.
그럼 A씨가 하루 동안 쏟아낸 데이터는 얼마나 될까? 다시 한 번 그의 하루를 되짚어보자. A씨가 지하철을 탈 때와 내릴 때 개찰구 단말기에 교통카드를 태그하게 되는데, 이때 A씨가 몇 시 몇 분 몇 초에 어느 역의 개찰구를 통과했는지에 대한 데이터가 생긴다. 그가 페이스북에서 한 활동도 그가 어떤 글에 관심을 가지며 어떤 친구관계가 형성됐는지 등을 알려주는 지표가 된다. 은행 업무를 볼 때는 언제 어느 계좌에 어떤 거래내역이 생겼는지가, 친구에게 모바일로 돈을 송금할 때도 언제 누구에게 얼마를 보냈는지가 모두 기록된다. 마지막으로 그가 취중에 전 여자친구에게 전화를 걸 때도 언제 누구에게 어디서 전화를 걸었는지에 대한 데이터가 생긴다. 이처럼 사람들은 일상 속에서 데이터를 계속 흘리고 다닌다.

모바일 기기와 SNS의 확산이 빅데이터 시대 열어
개인이 하루 동안에 생성해내는 데이터의 양은 아마 위에 묘사된 것보다 훨씬 많을 것이다. 그럼 지구상의 모든 사람들이 1년 동안 생성해내는 데이터는 얼마 정도일까? 최근 2년 동안 생성된 데이터의 양이 인류가 그전까지 생성한 데이터보다 양이 많다는 걸 고려할 때, 그 양은 상상 이상일 것이다.
데이터의 폭발적인 증가는 스마트폰과 같은 모바일 기기의 상용화와 SNS의 확산에서 기인한다. 개인의 일상에 깊이 관여하는 스마트폰이 사용자의 일거수일투족을 기록하며, 내가 보고 느끼고 말하고 사진을 찍는 모든 행위를 디지털 플랫폼인 SNS에 저장할 수 있기 때문이다. 이렇게 만들어진 방대한 양의 데이터가 ‘빅데이터(Big Data)’다. 2011년 맥킨지(McKinsey)보고서는 이를 ‘일반적인 데이터베이스 체계가 저장, 관리, 분석할 수 있는 범위를 초과하는 규모의 데이터’라고 정의했다. 다양한(Variety) 유형의 방대한(Volume) 데이터를 실시간(Velocity)으로 분석하고 활용하는 빅데이터 기술은 이렇게 3V의 특징으로 정리되고, 이 기술을 활용하는 기업들은 점차 많아지고 있다. IDC(국제데이터기업)에 따르면, 세계 빅데이터 시장 규모는 매년 39.4%씩 성장하고 있으며, 2015년에는 그 규모가 169억 달러에 이를 것으로 예상된다. 이에 못지않게 국내 빅데이터 시장도 꾸준히 성장하고 있는데, 한국콘텐츠진흥원은 2020년에는 약 900만 달러 규모에 이를 것으로 내다봤다.
현대사회는 점점 다변화되고 있다. 이를 예측하여 효율적으로 대응하는 것이 기업 성패의 관건이고, 바로 빅데이터의 활용이 개인 맞춤형 정보제공을 가능케 한다. 이미 해외에서는 기업의 빅데이터 활용이 활발하다. 미국에서는 빅데이터를 이용한 소셜데이팅(social dating) 서비스가 인기다. 이 업체들은 사용자들의 데이터를 분석해서 남자와 여자를 1대 1로 연결해준다. ‘여성은 적어도 40대가 되기 전에는 본인 나이대의 남성에게 가장 매력을 느낀다. 하지만 남성은 20대 청년이든 60대 할아버지든, 20대 초반의 여성을 가장 매력적이라고 느낀다’와 같은 흥미로운 결과도 소셜데이팅업체의 데이터 분석과정에서 나왔다. 오케이큐피드(OkCupid)라는 업체는 이런 흥미로운 사실들을 묶어 <데이터폭풍(Dataclysm)>이라는 책도 펴내 인기를 얻었다.
빅데이터 이용한 서울시 심야버스 노선 설정
국내 빅데이터 시장도 활발해지고 있다. 서울시는 심야버스 노선에 빅데이터를 적용했다. 노선번호가 N으로 시작하는 이 버스는 첫차가 자정에, 막차가 새벽 3시 반쯤 있는 심야노선이다. 새벽 거리 위에서 집에 가지 못해 발을 동동 구르는 서울시민들을 최대한 효율적으로 집에 데려다줄 방법을 모색하던 서울시는 빅데이터를 이용해 노선 최적화문제를 해결했다. 노선 최적화의 관건은 심야시간에 가장 유동인구가 많은 지역을 연결하는 것이다. 서울시는 대중교통 데이터와 KT가 제공한 휴대전화 이력 데이터를 분석해 지역별 유동인구를 파악했고, 이를 바탕으로 노선, 정류장 위치 그리고 배차 간격을 정했다. 2013년 9월부터 운행한 심야버스는 운행 3개월 후 집계한 자료에 따르면 하루 평균 버스 1대당 138명이 이용했다고 하는데, 이는 주간에 운영되는 버스보다 25% 이상 많다. 빅데이터를 활용해 시민들의 편의를 증진시킨 것이다.
‘뭐 먹지?’ 문제 해결한 ‘다이닝코드(Dining Code)’
‘오늘 뭐먹지?’ 거의 모든 사람들이 하루에 한번 이상 던지는 질문이 아닐까. 가장 중요한 ‘밥’에 대한 질문에 답을 주는 서비스, 바로 ‘다이닝코드(Dining Code)’다. 다이닝코드는 네이버, 티스토리, 다음 블로그의 맛집 데이터를 모아 자체 알고리즘으로 순위를 매겨 사용자에게 제공한다. 예를 들어 ‘가로수길 파스타’를 검색하면 블로그에서 데이터를 수집해 분석한 결과를 토대로 가로수길의 파스타집 순위를 보여준다. 블로거가 돈을 받고 쓴 맛집 글을 보고 식당에 갔다가 잔뜩 실망만 하고 돌아온 경험을 가진 이들이라면 맛집 검색의 훌륭한 대안이 될 수 있다.
신효섭 다이닝코드 대표는 “다이닝코드 내의 자체적인 블로거 평점 시스템으로 광고성 콘텐츠를 생산해내는 블로거들의 글은 순위에서 밀린다. 따라서 이 서비스 내에서는 광고성 짙은 글이 상위에 랭크될 일이 없다. 보다 공정한 결과를 위해 순위를 매길 때도 사람이 전혀 개입하지 않게 전 과정을 자동화했다”고 설명했다.
소비자의 신뢰를 얻는 것이 우선이라는 신 대표는 맛집 랭킹에서 더 나아가 사용자가 직접 참여하는 유저 플랫폼으로의 도약을 목표로 한다. 사용자가 ‘찜’이나 ‘라이크(like)’를 누르고 리뷰를 남길 수 있게 하면 개인 맞춤 랭킹도 제공할 수 있다. 2013년 12월 웹에서 오픈하고 작년 11월에 앱을 출시한 다이닝코드는 1년 사이에 트래픽이 230배 증가했고 현재는 하루에 3만~4만명이 방문한다.
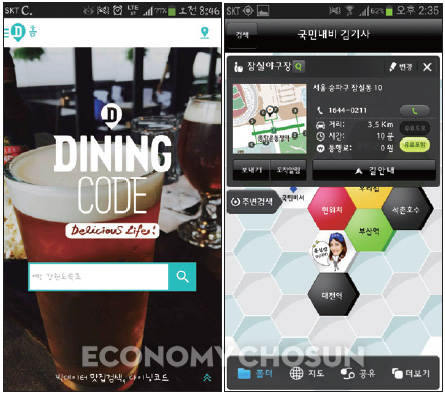
(우) 크라우드소싱으로 수집된 주행정보를 분석하여 최단거리를 알려주는 ‘김기사’.
크라우드소싱(crowdsourcing)으로 최단경로 찾는 ‘김기사’
그럼 ‘어떻게 가야 빠르지?’는 누가 알려줄까? 바로 크라우드소싱(crowdsourcing)을 이용한 국민 내비게이션, ‘김기사’다. 크라우드소싱은 쉽게 말해 대중(crowd)이 정보의 소스(source)가 되는, 즉 대중이 참여하는 콘텐츠 생산 방식이다. 이게 길안내랑 무슨 상관이 있다는 걸까. 현재 김기사 앱을 설치한 사용자가 850만명이다. 제주도, 울릉도를 포함한 전국 각지에 김기사로 길을 찾는 운전자들이 흩어져 있다. 그렇다면 이 850만 사용자의 주행 데이터를 실시간으로 모아 분석한다면? 서버에서 수집한 주행정보를 분석하면 어느 구간이 정체됐고 원활한지 보이는데, 그 결과를 토대로 최단경로가 나온다.
“기존 내비게이션은 콜택시들의 주행정보를 구입해 활용하는 방식이었다. 하지만 전국에 콜택시가 그렇게 많은 것도 아니고 콜택시가 전국 모든 길을 다니는 것도 아니다. 김기사는 전국의 모든 사용자로부터 데이터를 수집하기 때문에 정보량도 많고 업데이트 주기도 짧아 더 정확한 주행정보를 제공한다.”
‘김기사’를 출시한 박종환 록앤올 대표는 “크라우드소싱의 묘미는 사용자가 많아질수록 콘텐츠의 정확도가 높아진다는 것”이라고 설명했다. 그는 앞으로 한·중·일을 연결하는 실크로드를 꿈꾼다. 이미 국내 시장에서는 어느 정도 입지를 굳힌 김기사는 올해 일본시장에 진출했고, 그 다음 목표는 중국이다. 박 대표는 “국내 시장은 규모가 작아서 우리 기술의 잠재력이 백프로 발휘되진 않을 것이다. 일본과 중국 진출에 많은 기대를 걸고 있다”고 덧붙였다.
빅데이터로 사회현상 분석한 ‘뉴스젤리(News Jelly)’
‘겨울철 그 많던 군고구마장수는 어디로 갔을까?’라는 질문에 대한 답을 뉴스젤리(News Jelly)는 빅데이터에서 찾았다. 트위터에 군고구마를 치면 나오는 키워드를 분석했더니 ‘직화’ 그리고 ‘냄비’라는 키워드가 가장 많이 나왔다. 군고구마장수들이 거리에 좀처럼 보이지 않은 것은 몇 년 전부터 홈쇼핑에서 히트를 친 ‘직화냄비’ 때문이었다. 집에서도 거리에서 파는 군고구마맛을 낼 수 있는 직화(直火)냄비가 군고구마장수를 사라지게 했다. “일반 언론에서는 아마 관련자를 인터뷰하는 방식으로 취재했겠지만, 우리는 데이터로 알아보자고 생각했다”는 뉴스젤리 임준원, 정병준 공동대표의 말처럼 사회현상을 데이터로 분석할 수 있는 시대가 열렸다. ‘사람들이 진짜 알고 싶어 하는 것을 데이터로 풀어내고 싶다’는 취지로 2014년 시작한 뉴스젤리는 빅데이터를 이용한 콘텐츠 제작과 빅데이터 시각화 소프트웨어를 공급하는 서비스다. 현재 허핑턴포스트, 매일경제 등 4개 언론사에 빅데이터 콘텐츠를, 서울시에는 맞춤형 소프트웨어를 공급하고 있는데 특히 빅데이터 콘텐츠는 흥미로운 주제와 감각적인 그래픽으로 SNS에서 화제가 됐다. 임준원 대표는 “뉴스젤리의 목표는 빅데이터의 대중화”라고 설명했다.
“빅데이터 활용이 트렌드라고는 하지만 상위 1~ 2%의 대기업만 빅데이터를 활용하고 있다. 이건 빅데이터 분석 서비스가 비싸기 때문이다. 누구나 저렴한 가격에 쉽게 빅데이터를 활용할 수 있다면 훨씬 더 많은 일을 효율적으로 할 수 있을 것이다.”
자기계발서 열풍이 불면서 온라인 커뮤니티 내의 ‘ㅠㅠ’(우는 모습의 이모티콘) 언급량이 증가한 사실에서 자기계발서가 오히려 청년을 억누르고 있다는 흥미로운 결과가 도출됐는데, 이 또한 빅데이터가 있어서 가능했다. 이처럼 빅데이터는 콘텐츠의 새로운 보고(寶庫)다.

빅데이터로 일상 속 궁금증, 불편 해결
말 그대로 다양한 출처를 가진 방대한 양의 빅데이터. 어려운 개념이라고 지레 겁먹을 수도 있지만 들여다보면 ‘홍대에서 뭐 먹지?’, ‘집까지 어떻게 가지?’, ‘군고구마장수는 어디 갔지?’와 같은, 누구나 평소에 느낄 만한 궁금증을 해소해주는 친숙하고도 가까운 존재다. 사람들의 일상이 디지털화되면서 쏟아져 나온 데이터를 분석해 의미 있는 데이터로 재가공한다면 사람들이 정말 필요로 하는 정보 및 서비스를 제공할 수 있다는 것이 빅데이터가 가진 매력이자 무한한 가능성이다.